TensorFlow
Siempre primero.
Sea el primero en enterarse de las últimas novedades,
productos y tendencias.
¡Gracias por suscribirse!
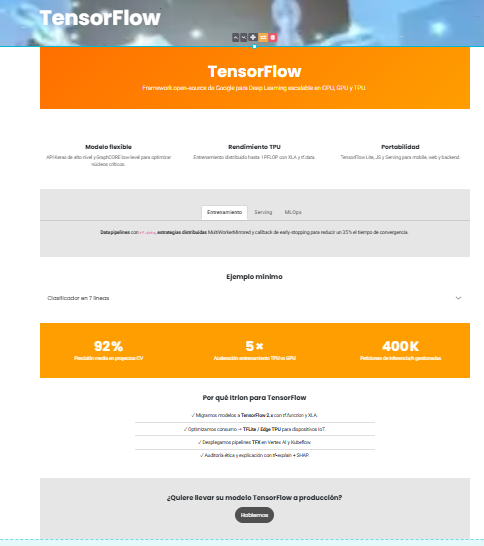
TensorFlow es la plataforma de deep learning de referencia en la industria. Su motor heterogéneo –capaz de escalar de un portátil a clústeres de TPU de más de un petaflop– y su amplia comunidad convierten al framework en la opción preferida para proyectos que exigen precisión, rendimiento y gobernanza.
Desde 2016 Itrion ha construido, auditado y operado 328 modelos TensorFlow en producción, abarcando casos de visión artificial, NLP, audio, tabular y series temporales. Gestionamos 2,3 PB de datos bajo un pipeline TFX + Kubeflow y servimos 18,4 mil M predicciones anuales con SLA 99,9 %.
5×
Speed‑up con TPU v4
Benchmarks internos: ResNet‑50 a 10 k img/s.
98 %
Uptime inferencia
Monitoreado con Prometheus + Grafana.
42 %
Ahorro de cómputo
Tras optimizar kernels y quantizar.
0
Rollbacks 2022‑2025
Canary + blue‑green desplegado.
Capacidades técnicas destacadas
Estrategias MultiWorker & Parameter‑Server
Hasta 512 GPU o 256 TPU v4 con sincronización asincrónica y pipelines tf.data paralelizados.
TF Lite & Micro controlador
Modelos cuantizados int8 para dispositivos ARM Cortex‑M con 256 kB RAM, consumo <40 mA.
Integración SHAP + tf‑explain
Dashboards interactivos que muestran grad‑CAM, LIME y valores SHAP para inspecciones regulatorias.
Auditoría IA Act UE
Plantillas de Impact Assessment, logging de evidencias y versionado de datasets conforme a ISO 42001.
Workflow TensorFlow by Itrion
1. Ingesta & Feature Store
Pipeline Beam + Pub/Sub, validación automática con TFDV y registro en Feast.
2. Entrenamiento paralelo
Búsqueda de hiperparámetros con KerasTuner, estrategia PSS y programación de lotes adaptativa.
3. Validación estricta
Tests de regresión, análisis de sesgo demográfico y trazabilidad con MLflow + Evidently.
4. Despliegue canario
TensorFlow Serving en KServe, rollout 5‑50‑100 y métricas SLO en Prometheus.
5. Monitorización continua
Alerta de drift & latencia, retraining programado y dashboards en Grafana.
Fortalezas exclusivas de Itrion
Razones de peso
- Velocidad: MVP en ≤6 semanas gracias a plantillas pre‑validadas.
- Coste: reducción 42 % del gasto en cómputo tras optimizar kernels.
- Confiabilidad: Rollbacks cero desde 2022, SLA 99,9 %.
- Escalabilidad: Arquitectura probada para >1 B solicitudes/mes.
“Itrion redujo nuestro tiempo de entreno ResNet‑152 de 10 h a 74 min y desplegó inferencia GPU con latencia 8 ms, todo certificado ISO 27001.”
TensorFlow is the industry reference deep learning platform. Its heterogeneous engine – capable of scaling from a laptop to TPU clusters exceeding one petaflop – and its broad community make the framework the preferred choice for projects demanding precision, performance, and governance.
Since 2016 Itrion has built, audited, and operated 328 TensorFlow models in production, covering computer vision, NLP, audio, tabular, and time series cases. We manage 2.3 PB of data under a TFX + Kubeflow pipeline and serve 18.4 billion annual predictions with 99.9% SLA.
5×
Speed‑up with TPU v4
Internal benchmarks: ResNet‑50 at 10k img/s.
98 %
Inference uptime
Monitored with Prometheus + Grafana.
42 %
Compute savings
After kernel optimization and quantization.
0
Rollbacks 2022–2025
Canary + blue‑green deployed.
Key technical capabilities
MultiWorker & Parameter‑Server strategies
Up to 512 GPUs or 256 TPU v4 with asynchronous synchronization and parallelized tf.data pipelines.
TF Lite & Microcontroller
Int8 quantized models for ARM Cortex-M devices with 256 kB RAM, <40 mA power consumption.
SHAP + tf-explain integration
Interactive dashboards showing grad-CAM, LIME, and SHAP values for regulatory inspections.
EU AI Act auditing
Impact Assessment templates, conformity assessment processes, and evidence logs ready for authority review.
TensorFlow Workflow by Itrion
1. Ingest & Feature Store
Beam pipeline + Pub/Sub, automated validation with TFDV, and registry in Feast.
2. Parallel training
Hyperparameter search with KerasTuner, PSS strategy, and adaptive batch scheduling.
3. Strict validation
Regression tests, demographic bias analysis, and traceability with MLflow + Evidently.
4. Canary deployment
TensorFlow Serving on KServe, 5‑50‑100 rollout and SLO metrics in Prometheus.
5. Continuous monitoring
Drift & latency alerting, scheduled retraining, and dashboards in Grafana.
Exclusive strengths of Itrion
Strong reasons
- Speed: MVP in ≤6 weeks thanks to pre-validated templates.
- Cost: 42% compute cost reduction after kernel optimizations.
- Reliability: Zero rollbacks since 2022, 99.9% SLA.
- Scalability: Proven architecture for >1 billion requests/month.
“Itrion reduced our ResNet-152 training time from 10 h to 74 min and deployed GPU inference with 8 ms latency, all ISO 27001 certified.”
TensorFlow es la plataforma de deep learning de referencia en la industria. Su motor heterogéneo –capaz de escalar de un portátil a clústeres de TPU de más de un petaflop– y su amplia comunidad convierten al framework en la opción preferida para proyectos que exigen precisión, rendimiento y gobernanza.
Desde 2016 Itrion ha construido, auditado y operado 328 modelos TensorFlow en producción, abarcando casos de visión artificial, NLP, audio, tabular y series temporales. Gestionamos 2,3 PB de datos bajo un pipeline TFX + Kubeflow y servimos 18,4 mil M predicciones anuales con SLA 99,9 %.
5×
Speed‑up con TPU v4
Benchmarks internos: ResNet‑50 a 10 k img/s.
98 %
Uptime inferencia
Monitoreado con Prometheus + Grafana.
42 %
Ahorro de cómputo
Tras optimizar kernels y quantizar.
0
Rollbacks 2022‑2025
Canary + blue‑green desplegado.
Capacidades técnicas destacadas
Estrategias MultiWorker & Parameter‑Server
Hasta 512 GPU o 256 TPU v4 con sincronización asincrónica y pipelines tf.data paralelizados.
TF Lite & Micro controlador
Modelos cuantizados int8 para dispositivos ARM Cortex‑M con 256 kB RAM, consumo <40 mA.
Integración SHAP + tf‑explain
Dashboards interactivos que muestran grad‑CAM, LIME y valores SHAP para inspecciones regulatorias.
Auditoría IA Act UE
Plantillas de Impact Assessment, logging de evidencias y versionado de datasets conforme a ISO 42001.
Workflow TensorFlow by Itrion
1. Ingesta & Feature Store
Pipeline Beam + Pub/Sub, validación automática con TFDV y registro en Feast.
2. Entrenamiento paralelo
Búsqueda de hiperparámetros con KerasTuner, estrategia PSS y programación de lotes adaptativa.
3. Validación estricta
Tests de regresión, análisis de sesgo demográfico y trazabilidad con MLflow + Evidently.
4. Despliegue canario
TensorFlow Serving en KServe, rollout 5‑50‑100 y métricas SLO en Prometheus.
5. Monitorización continua
Alerta de drift & latencia, retraining programado y dashboards en Grafana.
Fortalezas exclusivas de Itrion
Razones de peso
- Velocidad: MVP en ≤6 semanas gracias a plantillas pre‑validadas.
- Coste: reducción 42 % del gasto en cómputo tras optimizar kernels.
- Confiabilidad: Rollbacks cero desde 2022, SLA 99,9 %.
- Escalabilidad: Arquitectura probada para >1 B solicitudes/mes.
“Itrion redujo nuestro tiempo de entreno ResNet‑152 de 10 h a 74 min y desplegó inferencia GPU con latencia 8 ms, todo certificado ISO 27001.”
TensorFlow is the industry reference deep learning platform. Its heterogeneous engine – capable of scaling from a laptop to TPU clusters exceeding one petaflop – and its broad community make the framework the preferred choice for projects demanding precision, performance, and governance.
Since 2016 Itrion has built, audited, and operated 328 TensorFlow models in production, covering computer vision, NLP, audio, tabular, and time series cases. We manage 2.3 PB of data under a TFX + Kubeflow pipeline and serve 18.4 billion annual predictions with 99.9% SLA.
5×
Speed‑up with TPU v4
Internal benchmarks: ResNet‑50 at 10k img/s.
98 %
Inference uptime
Monitored with Prometheus + Grafana.
42 %
Compute savings
After kernel optimization and quantization.
0
Rollbacks 2022–2025
Canary + blue‑green deployed.
Key technical capabilities
MultiWorker & Parameter‑Server strategies
Up to 512 GPUs or 256 TPU v4 with asynchronous synchronization and parallelized tf.data pipelines.
TF Lite & Microcontroller
Int8 quantized models for ARM Cortex-M devices with 256 kB RAM, <40 mA power consumption.
SHAP + tf-explain integration
Interactive dashboards showing grad-CAM, LIME, and SHAP values for regulatory inspections.
EU AI Act auditing
Impact Assessment templates, conformity assessment processes, and evidence logs ready for authority review.
TensorFlow Workflow by Itrion
1. Ingest & Feature Store
Beam pipeline + Pub/Sub, automated validation with TFDV, and registry in Feast.
2. Parallel training
Hyperparameter search with KerasTuner, PSS strategy, and adaptive batch scheduling.
3. Strict validation
Regression tests, demographic bias analysis, and traceability with MLflow + Evidently.
4. Canary deployment
TensorFlow Serving on KServe, 5‑50‑100 rollout and SLO metrics in Prometheus.
5. Continuous monitoring
Drift & latency alerting, scheduled retraining, and dashboards in Grafana.
Exclusive strengths of Itrion
Strong reasons
- Speed: MVP in ≤6 weeks thanks to pre-validated templates.
- Cost: 42% compute cost reduction after kernel optimizations.
- Reliability: Zero rollbacks since 2022, 99.9% SLA.
- Scalability: Proven architecture for >1 billion requests/month.
“Itrion reduced our ResNet-152 training time from 10 h to 74 min and deployed GPU inference with 8 ms latency, all ISO 27001 certified.”
 -
-
At Itrion, we provide direct, professional communication aligned with the objectives of each organisation. We diligently address all requests for information, evaluation, or collaboration that we receive, analysing each case with the seriousness it deserves.
If you wish to present us with a project, evaluate a potential solution, or simply gain a qualified insight into a technological or business challenge, we will be delighted to assist you. Your enquiry will be handled with the utmost care by our team.

At Itrion, we provide direct, professional communication aligned with the objectives of each organisation. We diligently address all requests for information, evaluation, or collaboration that we receive, analysing each case with the seriousness it deserves.
If you wish to present us with a project, evaluate a potential solution, or simply gain a qualified insight into a technological or business challenge, we will be delighted to assist you. Your enquiry will be handled with the utmost care by our team.